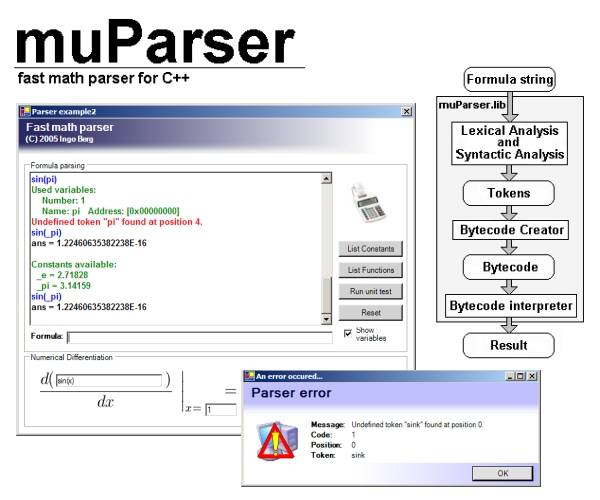
Many applications require the parsing of mathematical expressions. The main objective of this project is to provide a fast and easy way of doing this. muParser is an extensible high performance math parser library. It is based on transforming an expression into a bytecode and pre-calculating constant parts of it.
The math parser library is written in pure C++ and should compile on every standard-compliant compiler. I provide you with static libraries and a DLL version ready for implementation into your projects. The code has been tested using MS VC++ V7.1 and GCC V3.3.1. It reportedly works on BCB, too. I provide you with three demo projects in order to help you understand its usage.
Additional information about this parser can be found at its project homepage. An online class documentation for the math parser is available, too.
- Table of contents
- Introduction
- Features
- Adding the parser to your projects
- The parser interface
- Example code
- Background
- Benchmarks
- Related links
- License
The following is a list of the features currently supported by the parser library. The primary objective is to keep it as extensible as possible whilst ensuring a maximum parsing speed. Extending the parser is mostly based on allowing a user to add custom callbacks, which require only an absolute minimum of code. For instance, you need exactly two lines of code to add a new function. But extending the parser may not be necessary at all since it comes with a powerful default implementation. Here is the (incomplete) list of features:
- Easy to use
- Very fast
- User-defined operators
- binary operators
- postfix operators
- infix operators
- User-defined functions
- with a fixed number of up to five arguments
- with variable number of arguments
- with a single string argument (for database queries)
- User-defined constants.
- numeric constants
- string constants
- User-defined variables.
- unlimited in number
- definable at parser runtime by the parser
- assigning variables in terms of other variables is possible
- Custom value recognition callbacks
- support for binary and hex values.
- can be used to implement database queries
- Default implementation with many features
- Portability
- GNU Makefile included
- BCB Project files included
- MSVC 7.1 Project files for managed and unmanaged code
- ISO 14882 compliant code
- DLL version usable from every language able to use function exported in C-style
- Unit support
- Use postfix operators as unit multipliers (
3m -> 0.003).
This section gives an overview on the default features supported by the parser. The default implementation is defined in the class mu::Parser located in the file muParser.cpp. The DLL-version uses this class internally.
The following table gives an overview of the functions supported by the default implementation. It lists the function names, the number of arguments and a brief description.
| Name |
Argc. |
Explanation |
sin |
1 |
sine function |
cos |
1 |
cosine function |
tan |
1 |
tangens function |
asin |
1 |
arcus sine function |
acos |
1 |
arcus cosine function |
atan |
1 |
arcus tangens function |
sinh |
1 |
hyperbolic sine function |
cosh |
1 |
hyperbolic cosine |
tanh |
1 |
hyperbolic tangens function |
asinh |
1 |
hyperbolic arcus sine function |
acosh |
1 |
hyperbolic arcus tangens function |
atanh |
1 |
hyperbolic arcus tangens function |
log2 |
1 |
logarithm to the base 2 |
log10 |
1 |
logarithm to the base 10 |
log |
1 |
logarithm to the base 10 |
ln |
1 |
logarithm to base e (2.71828...) |
exp |
1 |
e raised to the power of x |
sqrt |
1 |
square root of a value |
sign |
1 |
sign function, -1 if x<0; 1 if x>0 |
rint |
1 |
round to nearest integer |
abs |
1 |
absolute value |
if |
3 |
if ... then ... else ... |
min |
var. |
min of all arguments |
max |
var. |
max of all arguments |
sum |
var. |
sum of all arguments |
avg |
var. |
mean value of all arguments |
The following table lists the default binary operators supported by the parser:
| Operator |
Meaning |
Priority |
= |
assignment* |
-1 |
and |
logical AND |
1 |
or |
logical OR |
1 |
xor |
logical XOR |
1 |
<= |
less or equal |
2 |
>= |
greater or equal |
2 |
!= |
not equal |
2 |
== |
equal |
2 |
> |
greater than |
2 |
< |
less than |
2 |
+ |
addition |
3 |
- |
subtraction |
3 |
* |
multiplication |
4 |
/ |
division |
4 |
^ |
raise x to the power of y |
5 |
*The assignment operator is special since it changes one of its arguments and can only by applied to variables.
This project comes as a library that allows you multiple choices for inclusion into your projects, depending only on your platform and your programming environment. The choices are: using static libraries, using a DLL or including the source code directly. The following table gives an overview of their applicability:
| Platform |
DLL |
static library |
source inclusion |
| Cygwin/Linux |
- |
(R) |
X |
| MSVC 6 |
X |
- |
- |
| MSVC 7.x |
X |
X |
X |
| Borland C++ |
(X) |
(R) |
(X) |
| other languages |
(X) |
- |
- |
(X) means that I have not been able to test this. All languages that are able to use DLLs that export plain C functions should be able to use this parser. Using the static libraries is possible only when using an identical version of the STL, otherwise you need to recompile the libraries.
(R) means recompiling the static libraries is necessary (Makefile for cygwin supplied with this project).
Using the DLL is the only way to use this parser with MSVC6 or languages other than C++. The DLL has an interface that exports all functions as plain C style functions. Due to the wrapper being necessary, there is some overhead associated with using the dynamic library.
The following files are required:
- muParserDLL.h
- muParser.lib
- muParser.dll
Include the header file in your project and add the lib file to the project resources. If you are using the Borland compiler, it may be necessary either to create a new lib from the DLL using implib or to convert the lib file. For more details on using DLLs, consult your compiler manual.
When linking with the static libraries, you have the choice between different library versions. Using the default libraries is only possible when using MSVC 7.x since they depend on the STL version used in your project. The lib file necessary for your project depends on the threading model and debug mode. The following table gives you an overview of the static libraries:
| Library name |
Threading model |
| muParser.lib |
Single threaded |
| muParserDbg.lib |
Single threaded (debug) |
| muParserMT.lib |
Multi threaded |
| muParserMT_Dbg.lib |
Multi threaded (debug) |
| muParserMTD.lib |
Multi threaded (DLL version) |
| muParserMTD_Dbg.lib |
Multi threaded (DLL version; debug) |
In order to keep the archive small, I do not provide you with binaries for the libraries. Please create them yourself. Click on the ParserLib project and select the appropriate compilation setup (Release, Debug, Debug (MTD) or Debug (Multithread)). To link the library, select the right one for your application, depending on your project settings. Next, either add lines like the following to your application or drag and drop the library to your project resources. Make sure to use the correct version, otherwise you will get plenty of linker errors originating from different versions of the runtime library used within the same project.
 Collapse | Copy Code
Collapse | Copy Code#if defined(_DEBUG)
#pragma comment(lib, "../ParserLib/muParserDbg.lib")
#else
#pragma comment(lib, "../ParserLib/muParser.lib")
#endif
The path might be different for your project, depending on where you put the library. Additionally, you have to include the file muParser.h in your source code. Finally, make sure the following header files are present in your project include path:
- muParser.h
- muParserBase.h
- muParserBytecode.h
- muParserCallback.h
- muParserDef.h
- muParserError.h
- muParserStack.h
- muParserToken.h
- muParserTokenReader.h
- muIParserTypes.h
If you have trouble using the lib files, include the sources directly or use the DLL.
For some platforms like cygwin/linux, including the source code is the most convenient way of using the parser. Due to the variety of Linux platforms and distributions out there, I can't provide you with a library for your specific platform/distribution. In other cases, it may be a convenient way to avoid linker conflicts originating from different versions of the runtime used by the parser and your project.
In order to use the parser, simply make sure all header files listed in the previous section are in the include path. Additionally, make sure to add the following source code files to your project/makefile:
- muParserBase.cpp
- muParser.cpp
The parser class and all related classes reside in the namespace mu (MathUtils). So make sure to either add a using:
Collapse | Copy Code using namespace mu;
to your files, or reference all classes with their complete name.
The following section gives an overview of the public parser member functions as well as of the functions exported by the DLL version of the parser.
[DLL interface]
Create a new instance handle. You can create as many different instance handles as you like. Each will internally reference a different parser object. When using the DLL, it is necessary to manually release any parser handle created by mupInit().
Collapse | Copy Code parser_handle hParser;
hParser = mupInit(); mupRelease(hParser);
[Parser class interface]
Code for creating a new parser object. (In the case of dynamic allocation, use new and delete for initialization and deinitialization.)
Collapse | Copy Code mu::Parser parser;
[DLL interface]
Setting the expression when using the DLL requires a valid parser handle and a pointer to const char pointing to the expression.
Collapse | Copy Code mupSetExpr(hParser, szLine);
See also: Example3/Example3.cpp.
[Parser class interface]
Setting the expression using the parser class requires a std::string containing the expression as the only parameter.
Collapse | Copy Code parser.SetExpr(line);
See also: Example1/Example1.cpp; Example2/WndMain.cpp; ParserLib/muParserTest.cpp.
Expression evaluation is done by calling the mupEval() function in the DLL version or the Eval() member function of a parser object. When evaluating an expression for the first time, the parser evaluates the expression string directly and creates a bytecode during this first time evaluation. Every successive call to Eval() will evaluate the bytecode directly unless you call a function that will silently reset the parser to string parse mode. Some functions invalidate the bytecode due to possible changes in callback function pointers or variable addresses. In this way, they effectively cause a recreation of the bytecode during the next call to Eval().
Internally, there are different evaluation functions. One for parsing from a string, and another for parsing from bytecode (and a third one used only if the expression can be simplified to a constant). Initially, Eval() will call the string parsing function which is slow due to all the necessary syntax checking, variable lookup, and bytecode creation. Once this function succeeds, Eval() will change its internal parse function pointer to either the bytecode parsing function or the const result function which is significantly (approx. 1000 times) faster. You don't have to worry about this, it's done automatically, just keep in mind that the first time evaluation of a new formula is significantly slower than any successive call to Eval().
[DLL interface]
Collapse | Copy Code double fVal;
fVal = mupEval(hParser);
See also: Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code double fVal;
try
{
fVal = parser.Eval();
}
catch (Parser::exception_type &e)
{
std::cout << e.GetMsg() << endl;
}
See also: Example1/Example1.cpp; Example2/WndMain.cpp.
Sometimes it is necessary to change the character sets that are used for token identifiers in order to avoid conflicts. The parser uses three different character sets.
- The name character set, is used for:
- function identifiers
- variable identifiers
- constant identifiers
- The operator character set, is used for:
- binary operator identifiers
- postfix operator identifiers
- The Infix operator charset is used for infix operator identifiers only
When using the default implementation mu::muParser directly, you can skip this section. (The DLL version uses the default implementation internally.)
[DLL interface]
Collapse | Copy Code mupDefineNameChars(hParser,
"0123456789_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
mupDefineOprtChars(hParser,
"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ+-*^/?<>=#!$%&|~'_");
mupDefineInfixOprtChars(hParser, "/+-*^?<>=#!$%&|~'_");
[Parser class interface]
Collapse | Copy Code parser.DefineNameChars("0123456789"
"_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
parser.DefineOprtChars("abcdefghijklmno"
"pqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ+-*^/?<>=#!$%&|~'_");
parser.DefineInfixOprtChars("/+-*^?<>=#!$%&|~'_");
See also: ParserLib/muParser.cpp; ParserLib/muParserInt.cpp.
Custom variables can be defined either explicitly in the code by using the DefineVar function or implicitly by the parser. Implicit declaration will call a variable factory function provided by the user. The parser is never the owner of its variables. So you must take care of their destruction in the case of dynamic allocation. The general idea is to bind every parser variable to a C++ variable. For this reason, you have to make sure the C++ variable stays valid as long as you process a formula that needs it. Only variables of type double are supported.
Explicitly in this context means you have to do add the variables manually in your application code. So you must know in advance which variables you intend to use. If this is not the case, have a look at the section on Implicit creation of new variables.
[DLL interface]
The first parameter is a valid parser handle, the second the variable name, and the third a pointer to the associated C++ variable.
Collapse | Copy Code double fVal=0;
mupDefineVar(hParser, "a", &fVal);
See also: Example3/Example3.cpp.
[Parser class interface]
The first parameter is the variable name and the second a pointer to the associated C++ variable.
Collapse | Copy Code double fVal=0;
parser.DefineVar("a", &fVal);
See also: Example1/Example1.cpp; Example2/WndMain.cpp; ParserLib/muParserTest.cpp.
Implicit declaration of new variables is only possible by setting a factory function. Implicit creation means that every time the parser finds an unknown token at a position where a variable could be located, it creates a new variable with that name automatically. The necessary factory function must be of type:
Collapse | Copy Code double* (*facfun_type)(const char*)
The following code is an example of a factory function. The example does not use dynamic allocation for the new variables although this would be possible too. But when using dynamic allocation, you must keep track of the variables allocated implicitly in order to free them later on.
Collapse | Copy Code double* AddVariable(const char *a_szName)
{
static double afValBuf[100];
static int iVal = 0;
std::cout << "Generating new variable \""
<< a_szName << "\" (slots left: "
<< 99-iVal << ")" << endl;
afValBuf[iVal++] = 0;
if (iVal>=99)
throw mu::Parser::exception_type("Variable buffer overflow.");
return &afValBuf[iVal];
}
See also: Example1/Example1.cpp.
In order to add a variable factory, use the SetVarFactory functions. Without a variable factory, each undefined variable will cause an undefined token error. Factory functions can be used to query the values of newly created variables directly from a database. If you emit errors from a factory function, be sure to throw an exception of type ParserBase::exception_type, all other exceptions will be caught internally and result in an internal error.
[DLL interface]
Collapse | Copy Code mupSetVarFactory(hParser, AddVariable);
See also: Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code parser.SetVarFactory(AddVariable);
See also: Example1/Example1.cpp.
Parser constants can either be values of type double or string. Constness refers to the bytecode. Constants will be stored by their value in the bytecode, not by a reference to their address. Thus accessing them is faster. They may be optimized away if this is possible. Defining new constants or changing old ones will reset the parser to string parsing mode thus resetting the bytecode.
The names of user defined constants may contain only the following characters: 0-9, a-z, A-Z, _, and they may not start with a number. Violating this rule will raise a parser error.
[DLL interface]
Collapse | Copy Code mupDefineConst(hParser, "_pi", (double)PARSER_CONST_PI);
mupDefineStrConst("strBuf", "hello world");
See also: Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code parser.DefineConst("_pi", (double)PARSER_CONST_PI);
parser.DefineStrConst("strBuf", "hello world");
See also: Example1/Example1.cpp; Example2/WndMain.cpp; ParserLib/muParserTest.cpp.
The parser allows the user to define a variety of different callback functions. Functions with a fixed number of up to five numeric arguments, functions with a variable number of numeric arguments, and functions taking a single string argument. In order to define a parser function, you need to specify its name, a pointer to a static callback function, and an optional flag indicating if the function is volatile. Volatile functions are functions that can not be optimized.
The static callback functions must be either one of the following types:
Collapse | Copy Code double (*fun_type1)(double);
double (*fun_type2)(double, double);
double (*fun_type3)(double, double, double);
double (*fun_type4)(double, double, double, double);
double (*fun_type5)(double, double, double, double, double);
double (*multfun_type)(const double*, int);
double (*strfun_type1)(const char *);
[DLL interface]
When using the DLL version, it is necessary to call a separate function for each type of callback. The following is a list of possible choices:
Collapse | Copy Code mupDefineStrFun(hParser, "StrFun", pStrCallback, false);
mupDefineFun1(hParser, "fun1", pCallback1, false);
mupDefineFun2(hParser, "fun2", pCallback2, false);
mupDefineFun3(hParser, "fun3", pCallback3, false);
mupDefineFun4(hParser, "fun4", pCallback4, false);
mupDefineFun5(hParser, "fun5", pCallback5, false);
mupDefineMultFun(hParser, "MultFun", pMultCallback);
See also: Example3.cpp.
[Parser class interface]
Defining callback functions by using the parser class directly is easier since there is only a single member function that is used for all kinds of callbacks. Since this member function is defined as a template internally, it automatically associates the right code to any given type of callback (as long as this type is listed above).
Collapse | Copy Code parser.DefineFun("FunName", pCallback, false)
See also: Example1/Example1.cpp; ParserLib/muParser.cpp; ParserLib/muParserInt.cpp.
The parser is extensible with different kinds of operators: prefix operators, infix operators and binary operators. Operators can be applied to numerical values only (not to string constants).
- Postfix operators are operators that succeed values. For instance, the factorial operator (
a! = a*(a-1)...*2*1). Another application for postfix operators is their use as multipliers that can be used for implementing units.
- Infix operators are operators like the unary minus which serves as a sign or the logical not "
!(a<9)".
- Binary operators can be defined in order to supplement or replace the built-in binary operators that require an additional parameter, the operator priority.
Both postfix and infix operators take callback functions of type fun_type1 like the following:
Collapse | Copy Code double MyCallback(double fVal)
{
return fVal/1000.0;
}
For defining postfix operators and infix operators, you need a valid parser instance, an identifier string, and an optional third parameter marking the operator as volatile (non optimizable).
[DLL interface]
Collapse | Copy Code mupDefineInfixOprt(hParser, "!", MyCallback);
mupDefinePostfixOprt(hParser, "M", MyCallback);
See also:Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code parser.DefineInfixOprt("!", MyCallback);
parser.DefinePostfixOprt("m", MyCallback);
See also:Example1/Example1.cpp; Example2/WndMain.cpp; muParserTest.cpp.
This parser has 15 built-in binary operators. Sometimes it might be necessary to add additional custom binary operators. Examples are shl or shr, the "shift left" and "shift right" operators for integer numbers. In order to add user defined operators, you need to assign a name, a callback function of type fun_type2, and a priority for each new binary operator. You are not allowed to overload built-in operators, this would result in an error being raised! For instance, let's consider the following callback function which should be assigned to a binary operator:
Collapse | Copy Code double pMyAddFun(double v1, double v2)
{
return v1+v2;
}
For the definition of binary operators, you need at least four parameters. The first is a valid parser handle, the second is the identifier of the operator, the third is the operator callback function, the fourth is the operator priority, and the optional fifth parameter is a flag of type bool marking the operator as volatile. (The examples below omits the last flag.) Having defined a proper operator callback function, you can add the binary operator with the following code:
[DLL interface]
Collapse | Copy Code mupDefineOprt(hParser, "add", pMyAddFun, 0);
See also:Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code parser.DefineOprt("add", pMyAddFun, 0);
See also:Example1/Example1.cpp; Example2/WndMain.cpp; muParserTest.cpp.
The Priority value must be greater or equal than zero (lowest possible priority). It controls the operator precedence in the formula. For instance, if you want to calculate the formula 1+2*3^4 in a mathematically correct sense, you have to make sure that addition has a lower priority than multiplication which in turn has a lower priority than the power operator. The most likely cases are that you assign an operator with a low priority of 0 (like and, or, xor) or a high priority that is larger than 6 (the priority of the power operator (^)). By assigning priority values already used by built-in operators, you might introduce unwanted side effects. To avoid this and make the order of calculation clear, you must use brackets in these cases. Otherwise, the order will be determined by the formula parsing direction which is from left to right.
Example A: Priority of shl equals priority of an addition; the order of the execution is from left to right.
Collapse | Copy Code 1 + 2 shl 1 => (1 + 2) shl 1
2 shl 1 + 1 => (s shl 1) + 1
Example B: Priority of shl is higher than the that of addition; shl is executed first.
Collapse | Copy Code 1 + 2 shl 1 => 1 + (2 shl 1)
2 shl 1 + 1 => (2 shl 1) + 1
If you encounter such conflicts or simply don't need the built-in operators, these can easily be deactivated using the EnableBuiltInOprt(bool) function. If you call this function, you must add binary operators manually. After all, without any operators you won't be able to parse anything useful. User defined operators come with approximately 10% decrease in parsing speed compared to built-in operators. There is no way to avoid that. They cause an overhead when calling their callback functions. (This is the reason why there are built-in operators.)
Collapse | Copy Code parser.EnableBuiltInOprt(false);
Keeping track of all variables can be a difficult task. For simplification, the parser allows the user to query the variables defined in the parser. There are two different sets of variables that can be accessed:
- Variables defined in the parser
- Variables used in the current expression
Since the usage of the necessary commands is similar, the following example shows querying the parser variables only.
[DLL interface]
For querying the variables used in the expression, exchange mupGetVarNum(...) with mupGetExprVarNum(...) and mupGetVar(...) with mupGetExprVar(...) in the following example. Due to the use of a temporary internal static buffer for storing the variable name in the DLL version, this DLL-function is not thread safe.
Collapse | Copy Code int iNumVar = mupGetVarNum(a_hParser);
for (int i=0; i < iNumVar; ++i)
{
const char *szName = 0;
double *pVar = 0;
mupGetVar(a_hParser, i, &szName, &pVar);
std::cout << "Name: " << szName << " Address: [0x" << pVar << "]\n";
}
See also: Example3/Example3.cpp.
[Parser class interface]
For querying the expression variables, exchange parser.GetVar() with parser.GetUsedVar() in the following example:
Collapse | Copy Code mu::Parser::varmap_type variables = parser.GetVar();
cout << "Number: " << (int)variables.size() << "\n";
mu::Parser::varmap_type::const_iterator item = variables.begin();
for (; item!=variables.end(); ++item)
{
cout << "Name: " << item->first << " Address: [0x" << item->second << "]\n";
}
See also: Example1/Example1.cpp, Example2/WndMain.cpp.
Querying parser constants is similar to querying variables and expression variables.
[DLL interface]
Due to the use of a temporary internal static buffer for storing the variable name in the DLL version, this DLL-function is not thread safe.
Collapse | Copy Code int iNumVar = mupGetConstNum(a_hParser);
for (int i=0; i < iNumVar; ++i)
{
const char *szName = 0;
double fVal = 0;
mupGetConst(a_hParser, i, &szName, fVal);
std::cout << " " << szName << " = " << fVal << "\n";
}
See also: Example3/Example3.cpp.
[Parser class interface]
The parser class provides you with the GetConst() member function that returns a map structure with all defined constants. The following code snippet shows how to use it:
Collapse | Copy Code mu::Parser::valmap_type cmap = parser.GetConst();
if (cmap.size())
{
mu::Parser::valmap_type::const_iterator item = cmap.begin();
for (; item!=cmap.end(); ++item)
cout << " " << item->first << " = " << item->second << "\n";
}
See also: Example1/Example1.cpp, Example2/WndMain.cpp.
The parser default implementation (muParser.cpp) scans expressions only for floating point values. Custom value recognition callbacks can be used in order to implement support for binary, hexadecimal or octal numbers. These functions are called during the string parsing and allow the user to scan portions of the original expressions for values. Their callback functions must be of the following type:
Collapse | Copy Code bool (*identfun_type)(const char_type*, int&, value_type&);
If the parser reaches a position during string parsing that could host a value token, it tries to interpret it as such. If that fails, the parser successively calls all internal value recognition callbacks in order to give them a chance to make sense out of what has been found. If all of them fail, the parser continues to check if it is a variable or another kind of token.
In order to perform the task of value recognition, these functions take a const char pointer, a reference to int, and a reference to double as their arguments. The const char pointer points to the current formula position. The second argument is the index of that position. This value must be increased by the length of the value entry if one has been found. In that case, the value must be written to the third argument which is of type double.
The next code snippet shows a sample implementation of a function that reads and interprets binary values from the expression string. The code is taken from muParserInt.cpp, the implementation of a parser for integer numbers. Binary numbers must be preceded with a # (i.e., #1000101).
Collapse | Copy Code bool ParserInt::IsBinVal(const char_type *a_szExpr,
int &a_iPos, value_type &a_fVal)
{
if (a_szExpr[0]!='#')
return false;
unsigned iVal = 0, iBits = sizeof(iVal)*8;
for (unsigned i=0; (a_szExpr[i+1]=='0' ||
a_szExpr[i+1]=='1') && i<iBits; ++i)
iVal |= (int)(a_szExpr[i+1]=='1') << ((iBits-1)-i);
if (i==0)
return false;
if (i==iBits)
throw exception_type("Binary to integer conversion error (overflow).");
a_fVal = (unsigned)(iVal >> (iBits-i) );
a_iPos += i+1;
return true;
}
Once you have the callback, you must add it to the parser. This can be done with:
[DLL interface]
Collapse | Copy Code mupAddValIdent(hParser, IsBinVal);
See also: Example3/Example3.cpp.
[Parser class interface]
Collapse | Copy Code parser.AddValIdent(IsBinVal);
See also: ParserLib/muParserInt.cpp.
Removing variables and constants can be done all at once using ClearVar and ClearConst. Additionally, variables can be removed by name using RemoveVar. Since the parser never owns the variables, you must take care of their release yourself if they were dynamically allocated. If you need to browse all the variables for that purpose, have a look at the chapter explaining how to query parser variables.
[DLL interface]
Collapse | Copy Code mupClearConst(hParser);
mupClearVar(hParser);
mupRemoveVar(hParser, "a");
[Parser class interface]
Collapse | Copy Code parser.ClearConst();
parser.ClearVar();
parser.RemoveVar("a");
In the case of an error, both parser class and the parser DLL provide similar methods for querying the information associated with the error. In the parser class, they are member functions of the associated exception class mu::Parser::exception_type, and in the DLL version, they are normal functions.
These functions are:
exception.GetMsg() / mupGetErrorMsg() - returns the error message. exception.GetExpr() / mupGetExpr() - returns the current formula (if a formula is set) exception.GetToken() / mupGetErrorToken() - returns the token associated with the error (if applicable) exception.GetPos() / mupGetErrorPos() - returns the current formula position (if applicable) exception.GetCode() / mupGetErrorCode() - returns the error code.
The following table lists the parser error codes. The first column contains the enumeration values as defined in the enumeration mu::EErrorCodes located in the file muParserError.h. Since they are only accessible from C++, the second column lists their numeric code and the third column contains the error description.
| Enumeration name |
Value |
Description |
ecUNEXPECTED_OPERATOR |
0 |
Unexpected binary operator found |
ecUNASSIGNABLE_TOKEN |
1 |
Token can't be identified |
ecUNEXPECTED_EOF |
2 |
Unexpected end of formula (example: "2+sin(") |
ecUNEXPECTED_COMMA |
3 |
An unexpected comma has been found (example: "1,23") |
ecUNEXPECTED_ARG |
4 |
An unexpected argument has been found |
ecUNEXPECTED_VAL |
5 |
An unexpected value token has been found |
ecUNEXPECTED_VAR |
6 |
An unexpected variable token has been found |
ecUNEXPECTED_PARENS |
7 |
Unexpected parenthesis, opening or closing |
ecUNEXPECTED_STR |
8 |
A string has been found at an inappropriate position |
ecSTRING_EXPECTED |
9 |
A string function has been called with a different type of argument |
ecVAL_EXPECTED |
10 |
A numerical function has been called with a non value type of argument |
ecMISSING_PARENS |
11 |
Missing parens. (example: "3*sin(3") |
ecUNEXPECTED_FUN |
12 |
Unexpected function found (example: "sin(8)cos(9)") |
ecUNTERMINATED_STRING |
13 |
Unterminated string constant (example: "3*valueof("hello)") |
ecTOO_MANY_PARAMS |
14 |
Too many function parameters |
ecTOO_FEW_PARAMS |
15 |
Too few function parameters (example: "ite(1<2,2)") |
ecOPRT_TYPE_CONFLICT |
16 |
Binary operators may only be applied to value items of the same type |
ecSTR_RESULT |
17 |
Result is a string |
ecINVALID_NAME |
18 |
Invalid function, variable or constant name. |
ecBUILTIN_OVERLOAD |
19 |
Trying to overload built-in operator |
ecINVALID_FUN_PTR |
20 |
Invalid callback function pointer |
ecINVALID_VAR_PTR |
21 |
Invalid variable pointer |
ecNAME_CONFLICT |
22 |
Name conflict |
ecOPT_PRI |
23 |
Invalid operator priority |
ecDOMAIN_ERROR |
24 |
Catch division by zero, sqrt(-1), log(0) (currently unused) |
ecDIV_BY_ZERO |
25 |
Division by zero (currently unused) |
ecGENERIC |
26 |
Generic error |
ecINTERNAL_ERROR |
27 |
Internal error of any kind. |
[DLL interface]
Since dynamic libraries with functions exported in C-style can't throw exceptions, the DLL version provides the user with a callback mechanism to raise errors. Simply add a callback function that does the handling of errors. Additionally, you can query the error flag with mupError(). By calling this function, you will automatically reset the error flag!
Collapse | Copy Code void OnError()
{
cout << "Message: " << mupGetErrorMsg() << "\n";
cout << "Token: " << mupGetErrorToken() << "\n";
cout << "Position: " << mupGetErrorPos() << "\n";
cout << "Errc: " << mupGetErrorCode() << "\n";
}
...
mupSetErrorHandler(OnError);
fVal = mupEval(hParser);
if (!mupError()) cout << fVal << "\n";
See also: Example3/Example3.cpp.
[Parser class interface]
In the case of an error, the parser class raises an exception of type Parser::exception_type. This class provides you with several member functions that allow querying the exact cause as well as additional information for the error.
Collapse | Copy Code try
{
...
parser.Eval();
...
}
catch(mu::Parser::exception_type &e)
{
cout << "Message: " << e.GetMsg() << "\n";
cout << "Formula: " << e.GetExpr() << "\n";
cout << "Token: " << e.GetToken() << "\n";
cout << "Position: " << e.GetPos() << "\n";
cout << "Errc: " << e.GetCode() << "\n";
}
See also: Example1/Example1.cpp.
If you put all this together, you get the source code for a small application. The application defines a parser variable ("a") and adds a user defined function named "MyFunc". When using the parser, make sure that you don't forget to catch the Parser::exception_type in your application. It contains detailed information helping you to find syntax errors in your formula.
Collapse | Copy Code #include "muParser.h"
double MyFunction(double a_fVal)
{
return a_fVal*a_fVal;
}
int main(int argc, char* argv[])
{
using namespace mu;
try
{
double fVal = 1;
Parser p;
p.DefineVar("a", &fVal);
p.DefineFun("MyFunc", MyFunction);
p.SetFormula("MyFunc(a)*pi+min(10,a)");
std::cout << p.Eval() << endl;
}
catch (Parser::exception_type &e)
{
std::cout << e.GetMsg() << endl;
}
return 0;
}
First step is the parsing of the expression string. During this stage, the parser locates all relevant tokens such as values, variables, functions, and operators. The tokens will be stored in two different stacks. One for values, and one for operators, functions and brackets.
During the first parsing run, the bytecode will be generated. Bytecode code can be seen as a recording of stack operations. Once the parsing is done, the function pointer of the main parse routine will be set to the bytecode parsing function. If you change the expression after every call to Calc(), you will not benefit from the performance increase.
Once the expression has been transformed into bytecode, token identification and syntax verification is no longer necessary because the formula has already been verified.
This section will give you a short introduction of how the bytecode looks like. Following now is the bytecode for the formula a*sin(min(pi,b))+10:
The next picture shows an example of the parser bytecode. It will give you an impression of how the internal representation of an expression looks like. The expression is stored in reverse Polish notation, constant parts have been precalculated before, pointers and values are stored inline.
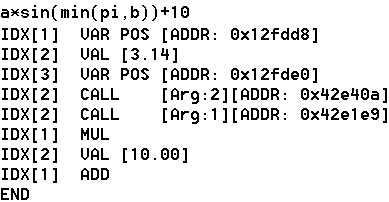
| Keywords: |
|
IDX[...] |
marks a position in the value array. |
VAL |
marks a value entry, the next 32 bytes represent an integer value. |
VAR |
marks a variable entry, the next bytes contain a sign flag and an address. |
CALL |
marks a function entry, the next bytes contain the argument count and the address of that function. |
MUL |
marks an operator entry. |
ADD |
marks an operator entry. |
- Write variable at address 0x12fdd8 with positive sign, at value array position 1.
- Write value 3.14 ("
pi") at position 2 of the value array.
- Write variable at address 0x12fde0 with positive sign, at value array position 3.
- Call the binary function at address 0x42e40a ("
min"); use the last two written values as arguments and write the result at position 2 in the value array.
- Call the unary function at address 0x42e1e9 ("
sin"); use the last written value as argument and overwrite it with the function result.
- Multiply the two uppermost values in the value array and store the result at a position one below the current one. (Operators store their result always in a position 1 below the current one, because they reduce two values to one by applying the operator to them.)
- Write value 10 at position 2 of the value array.
- Add the two uppermost values (position 1 and 2), and store the result at position 1.
- End of calculation, the result can be retrieved from position 1.
Finally, I'd like to give you some benchmarks. The benchmarking was done on an Intel Pentium P-4 with 2.6 GHz, with a version compiled by using MSVC++ 7.1 (Standard edition). The diagram shows the number of evaluations per second vs. expression length. I compared both the static lib and the DLL version with two other parsers that are freely available on the net, are very fast and have a similar set of features. One of them is a commercial product.
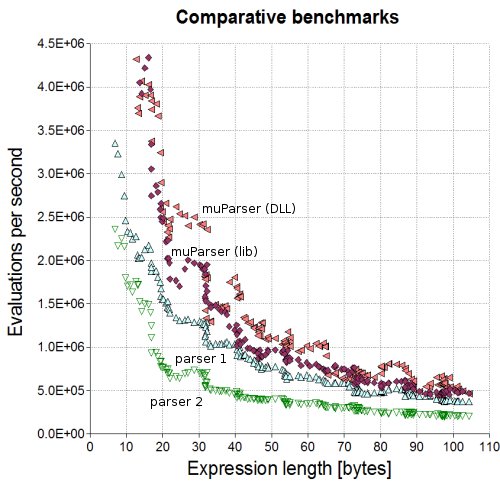
A higher curve means better performance. Expressions were created randomly. They used only sin and cos functions and contained multiple variables and constants. In order to smoothen the curves, each point represents the value of a running average over 10 sample expressions.
This library is distributed as freeware. You are free to use it for both non-commercial and commercial use. In order to use it, you have to agree to the license text below. If you use the library, I consider it appropriate to give me credit at some place. This can either be the About dialog of your application or the documentation of your software. If you like this project, I encourage you to support it by:
- sending me a brief description of how you use it in your project.
- sending me bug reports.
- voting for this project on CodeProject.
Copyright (c) 2004, 2005 Ingo Berg
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
If you found this article interesting, the following links might interest you:
- Qtiplot.
A platform independent program for scientific data analysis, by Ion Vasilief. It uses the parser for calculating the Jacobean matrix used in nonlinear Gauss Newton fitting of arbitrary curves.
- Transition Maker 2.
An interesting program written by Patrick Leabo that can be used for creating transitions for blending home movie sequences. The parser is used to support calculation of the gradient pattern that serves as the base for those transitions.



 程序开发
程序开发